ABOUT CLIENT
The client is a non-profit organization representing a group of investors launching an innovative product in the area of civic data collection, aggregation, and analysis
BUSINESS CONTEXT
Increasing attention to information freedom creates new possibilities for open data initiatives all over the US. One of such non-profit groups was able to create an idea, develop it further, and find support in government state structures to plan and start the development of a product aimed at integrating data generated by many specialized institutions. The product aims at creating rich datasets useful to everyone from interested individuals to businesses, which can rely on this data for estimating, planning and decision making
CHALLENGE
It appeared that a lot of data becomes public as a result of various initiatives and new data transparency laws. Such information is usually scattered, hard to find, and even harder to interpret. Civic Journals carefully collects, processes and groups this information making it available to others. There is a lot of data, and along with interpretation speed, the solution also had to be:
- Durable. The non-profit organization wanted to minimize support efforts since they didn’t want to support an army of DevOps and support engineers handling performance spikes and occasional failures
- Verified. The continuous Integration approach should be used to constantly verify the implementation by running unit, functional and nightly tests, fully covering current implementation. A bug found during manual testing should be an exceptional event
- Monitored. Necessary system statistics collection and monitoring should be done easily when needed
- Scalable. New data is always coming, new datasets get added, and a certain level of expected scalability should be put into the initial system design
- Cost-effective. While providing reasonable datasets processing latency, the system should be able to support datasets size growth without seriously increasing infrastructure maintenance costs
- Flexible. Only a few data-providing organizations are willing to do additional work pushing data into the system. Civic Journals should be ready to do most of the heavy lifting work by finding, downloading, parsing, and processing the data in an arbitrary format
SOLUTION
For the Civic Journals client, we’ve built a big data solution for integrating public statistics sources and increasing information transparency. Assuming data volumes along with the needed tooling set and scalability requirements, the Amazon AWS cloud platform was the most appropriate choice for building the project. Amazon provides a rich set of solutions for every need of high-loaded projects. What’s more, Amazon solves many maintenance routines assuming proper setup and smart architecture and enabling one-click scalability in reasonable margins
PRIMARY SYSTEM MODULES
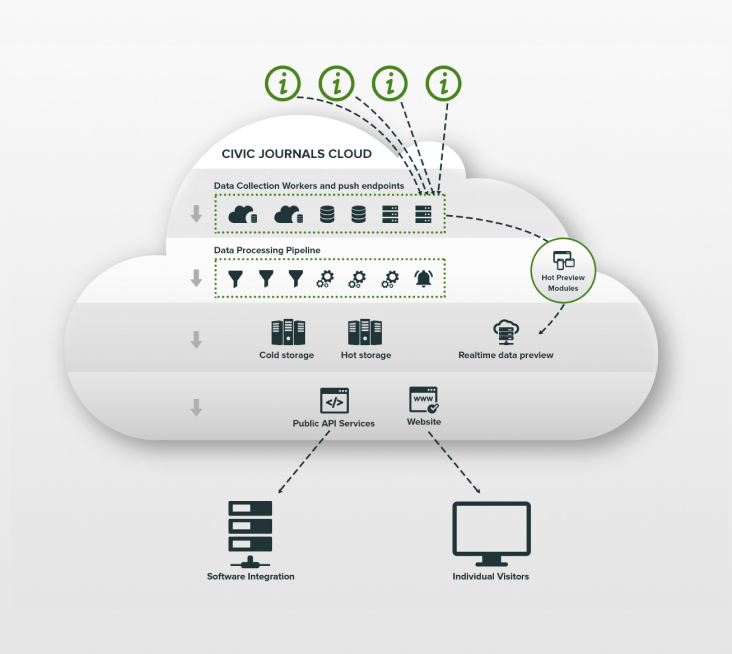
- Dataset fetchers. Integrated into a single workflow, many different pluggable modules are available to connect external data providers to the system. Some of them are ready to push their data directly to the system via an API, some publish machine-friendly files to their file servers, and some are just uploading HTML pages or pdf attachments on their website. A flexible infrastructure handles initial data acquisition
- Data storage. A few different database solutions host the data. The system transparently switches and moves data between hot and cold storage and a few caches, optimizing access times along with storage costs
- Dataset processors. Another kind of pluggable process raw data created during the previous step. Parse documents extract meaningful numbers and cook standard CJ datasets. This could be a simple solution, but often the aggregation scenarios are rather non-trivial, since many CJ datasets are sometimes a product of one initial input batch, possibly passing several computational and grouping steps. Adding data volume requirements, a flexible MapReduce solution had to be implemented – a generally slower, but ultimately scalable distributed computational algorithm. Standalone workers are plugged into certain steps of this algorithm, creating hybrid data cooking pipeline, able to solve the task in an easily adjustable manner
- Hot Preview. MapReduce solutions came at a cost: while providing high throughput, it harmed latency – newly available datasets were ready after a considerable delay. In order to level off this constraint, something usually referred to as an λ-architecture was applied. It means that once new data comes into the system, processing workflow splits into two branches: one branch runs normal MapReduce flow, while the other creates a preview of the result. This preview does not guarantee absolute accuracy, introducing some error margin or somehow incomplete representation, but gives a sneak peek into the end result, being eventually replaced with 100%-accurate results of the full flow