03 /
Case Studies
Case Studies
— Cases / BI · Big Data · Information Technology · Social
Demographic Big Data Processing
Fragmented US civic data — collected, processed, and made useful.

Civic Data · USA
BI
Big Data
Information Technology
Social
Industry
Civic data processing
Location
USA
Duration
16 months
Cloud
AWS
I
— About the client
A US non-profit building a platform that collects and analyzes public data from government and other institutions.
II · The brief
— Challenge
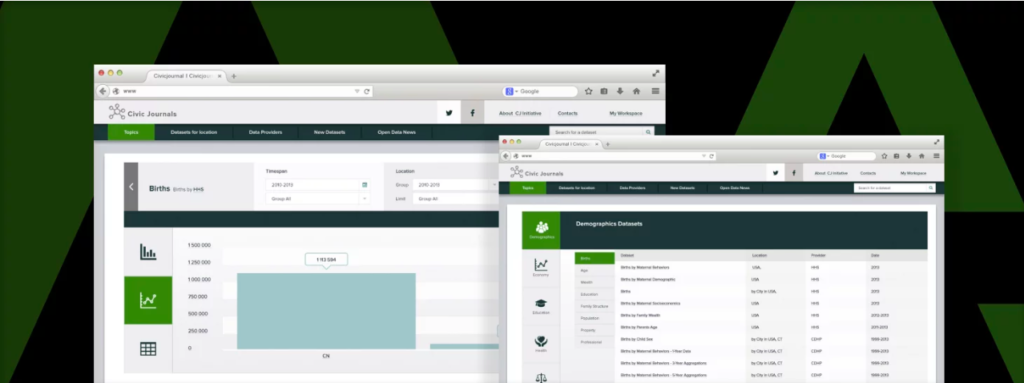
Context
Public data is scattered across incompatible formats and hard to use at scale. The system had to work reliably with minimal operational overhead.
— KEY OBJECTIVES
01
Ingest data from APIs, file servers, HTML pages, and PDFs
02
Scale without raising infrastructure costs significantly
03
Provide quick results while processing fully accurate data in the background
04
Run continuously with minimal manual intervention
II
III · Our approach
— Solution
We built the platform on AWS using a hybrid MapReduce + λ-architecture pipeline — fast previews from one branch, fully accurate results from the other — with pluggable fetchers for each data source type and transparent hot/cold storage switching.


III
IV · The outcome
— Results
The platform successfully processes large, heterogeneous civic datasets with minimal ops effort. It serves individuals, researchers, and businesses for planning and decision-making.
01
Cloud
AWS
02
Duration
16 months
03
Ops effort
Minimal
04
Users
Individuals · Researchers · Business
VI
Contact
Let's get started.
Tell us about your team and your stack. We'll bring the right DevOps engineers.